Misunderstood Misfits – The T2 Instance

We are going to take a simple but often misunderstood AWS methodology / feature and drag it out into the unapologetic sunlight via my way of looking at things. I tend to deal with IT professionals from all spectrums of the scale, so in the finest tradition of compromise, we are going to soar between 30,000 and 500 feet on this one.
T2 Instances help us get to the elusive “Goldilocks” zone in our lower level capacity mapping in the AWS Cloud. It’s the architectural equivalent of sharing a meal with your significant other – done right, everyone walks away happy, feeling like they nailed their order, and that they (for once) didn’t over eat. However, if you’ve ever tried to “share” something when the both of you are ravenous, you know just how well that works out. It doesn’t, and enviably someone ends with a fork stuck in the top of someone’s hand like a bad Tom & Jerry cartoon.
The major benefit of the T2 instance class is that you get a percentage of an instance’s CPU power to leverage against your workloads at a very low price. As we all operate in a give-and-take world, the consideration here is that you aren’t allowed to constantly consume more than your allocated portion of the processor time. It’s sort of like bogarting too many fries off that shared plate. You can get away with it so many times before, {{!BAM!}}, your hand gets slapped.
Baseline
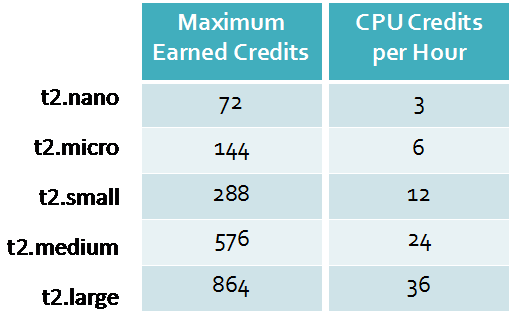
Getting to the technicalities, each of the T2 instance sizes allows for different level of constant access and expected use the available CPU – this is called the baseline.

The diagram above shows the baseline expectations for each T2 instance size. To make sure you are using the right instance size, you can see what baseline you can operate in.
For example, if you have an application/workload that is going to use very little CPU, equal to or less than an average of 5% of one processor for an hour, then a t2.nano is a good fit. If you had an application/workload that would take up less than an average of 20% of one processor, but more than 10%, then a t2.small is the T2 for you.
The t2.nano through the t2.small are 1 vCPU instances. The t2.medium and t2.large are 2 vCPU instances. The trick to making sure you are walking the line using the medium and large T2s is to understand that the baseline is an aggregate of the both vCPUs. For example, if you use 100% of a single vCPU and a 5% of the other, your CloudWatch metrics will show 55% utilization.
With either one or two processors, the expectation is clear – stay under the baseline and you’ll get constant performance. Well, what happens when your workload gets hungry for more?
In most cases, AWS expects that you are going to occasionally soar past the baseline. Really, asking a system to boot using less than an average of 5% of its CPU is unrealistic. (It’s like the idea that people want more hotdog bun than hotdog. - What rocket scientist came up with that??)
Credits
To address the inevitable over-use of the processor, AWS implements CPU credits. Single processor T2 instance sizes start you off with 30 credits, while dual processor sizes start you with 60 credits.
Credits equate to one minute of full CPU performance against one vCPU core. AWS is agonizingly literal about this – they track the utilization of the vCPU’s by the millisecond. So you can and do consume fractions of a credit as your system works the processor, but at least you are charged an exact amount as opposed to getting rounded up on. You can trust but verify the state of your systems and pools using CloudWatch metrics and alarms. AWS stays very much above board on this.
CPU Credits are the foundation of the T2 instance operation. When you are running your system, you are constantly consuming, and, in some cases, banking credits. This is where it gets a wee bit complicated to plan the use of T2 instances in a steady-state/production environment, and why a lot of people just use them for development or sandboxing use cases.
Basically, AWS provisions each T2 instance size with a large starting pool of credits, and then feeds it enough over the course of each hour to run at its baseline level. If you consume more than the credits you are given in an hour, the pool goes down. If you consume less, you get back the hours that you didn’t use. Each credit you earn is good for 24 hours in the bank. If you don’t use that particular credit, it expires and is taken off that instance’s pool ledger.
Each T2 instance type has a maximum pool size to take into account as well – but the ebb and flow of credits is more important to understand as it is your planning metric. The pool is your safety margin.
Honestly, one of the best explanations of credit expenditure and banking is straight from the AWS online manual entry on T2 instances:
[I]f a t2.small instance had a CPU utilization of 5% for the hour, it would have used 3 CPU credits (5% of 60 minutes), but it would have earned 12 CPU credits during the hour, so the difference of 9 CPU credits would be added to the CPU credit balance. Any CPU credits in the balance that reached their 24-hour expiration date during that time (which could be as many as 12 credits if the instance was completely idle 24 hours ago) would also be removed from the balance. If the amount of credits expired is greater than those earned, the credit balance will go down; conversely, if the amount of credits expired is fewer than those earned, the credit balance will go up.
AWS has a pretty “fair” system for helping you utilize T2 instances. However, if you are undersized too far, you will exhaust your pool. Once you reach a zero pool balance, AWS will start lowering your access to the vCPU core over 15 minutes until you are throttled down to the baseline expectation of the instance type you provisioned. While a fair and balanced response to using too many resources, it will feel like your application is bogging down and your CPU KPI’s will look as though the system is not stressed. Don’t be fooled! You’re being starved for your gluttony.
Admittedly, there are a lot more nuances working with T2’s than with all the other instance sizes in AWS, but there is a financial benefit, for sure, as a T2 instance tends to be 40-50% cheaper than their closest M class cousins.
The T2 class excels at single server workloads – or in other words single uniform tasks. File servers, file transfer servers, and other “You’ve got one job” roles that you can develop/predict an average workload on. Picking up jobs from a queue and processing tasks is another place where they find a happy purpose. I love using them to support Continuous Integration (CI) and Continuous Delivery (CD) tools – mostly because of the predictable nature of those workloads’ resource needs. , I also like to keep those types of systems up in a steady-state to handle the needs of Dev and QA teams. Devies and QA Cops are a hair trigger on the panic button in my experience as an Ops Monkey, and I’d rather not move their cheese on tools they see as critical.
(Some things, like team-critical toolsets, I still am bearish on blinking in and out of existence, even if the load on them isn’t constant – T2s let me look at not compromising cost vs consistency in these cases.)
Using T2s as web origin servers for a website fronted by a CDN, or as a read-replica feeding an ElastiCache node is another interesting use of the instance type. Sometimes when I suggest people try this, their eyes bug out. However, the network throughput of a T2 instance is on par with the other t-shirt sized instances in its class, and oddly in some cases there is a quick 1G burst of throughput before they settle into a steady state comparable with their like-sized cousins. At the very least, you should consider load testing such a scenario if you are looking for some pennies to squeeze out of a budget.
Where they don’t fit in very well at all is load balanced workloads working as a close knit group of servers. T2s aren’t really team players. Putting T2s in an auto scaling group offers a lesson that I can share my scars with you on, so you can avoid it. They don’t play nice under such scrutiny, and tend to make for some very grumpy load balancers.
Theoretical spreadsheet jockeys often come to the beer napkin conclusion that acquiring T2s on the spot market would support a fairly powerful queue tasking workload in theory, yes, however AWS would like to stay in business, so you won’t find the uber-frugal T2s on the spot market.
Finally, don’t expect the T2 instances to give you stellar disk performance, as none of them support EBS Optimized instance feature. However a nice, steady, under baseline use case might not need that feature as much and it’s easy enough to uncover in the KPI’s.
So, coming full circle back to our starting analogy (and oh do I love analogies…), how hungry your application/use case is determines if the T2 instance family is appropriate for you. Hopefully you’ll consider these little guys for a job other than a sandbox sometime soon.
Related Blog Posts















































