
From veterans to tax payers, contractors to military personnel, the U.S. government is one of the world’s largest harbors of personally identifiable information (PII). Year after year of security breaches has done nothing but destroy public trust in the government’s ability to protect PII about citizens, employees, and contractors.
Protecting PII is a tricky business. Although NIST categorizes what constitutes PII in its Guide to Protecting the Confidentiality of Personally Identifiable Information, even once you understand what PII is in government there remains the challenge of determining where this information is located and stored. Typically, PII resides in either structured data sources such as databases, or in unstructured information such as emails, documents, and other file types. The problem is worsened by the fact that unstructured data can travel anywhere – from the desktop, to a tablet, smartphone, or into the cloud.
This all raises a number of questions and concerns:
• How do you identify which unstructured information contains PII?
• How do you make employees, contractors and partners aware that certain files contain PII?
• How do you involve information creators in the protection of PII?
• What security controls are available?
DLT partner, TITUS, explains how it works in the whitepaper. Below are some key points to consider:
Step 1: Identify your PII
Automated categorization, marking, and metadata tagging of PII are key processes which can be used to identifying and determining where PII is located and stored.
Automated categorization can be used to scan existing documents and emails to try to identify PII and is recommended for large file repositories. The problem is that this method can throw up false positives and negatives.
To tag PII as it’s being created, marking and tagging have long been used in government to identify that an email or document contains sensitive information (see an example below).
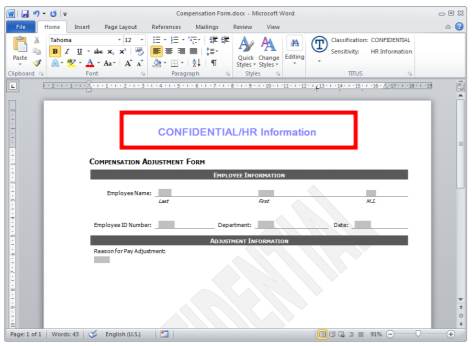
Metadata tagging works by inserting metadata into unstructured information. This then tags files that contain sensitive PII so that other systems, such as email gateways, DLP systems, and search engine can read and act on that metadata.
Step 2: Educate and Build Awareness of PII
Inadvertent data loss is the number one reason for data breaches, and NIST emphasizes education, training, and awareness as a vital operational safeguard for PII protection. Training on the proper identification and handling of PII is a must for any organization. But how do you get employees to adhere to the training best practices days, weeks, or months down the line? Continuing education is needed to educate users while they are working. For example, automated content warnings and markings keep users engaged in the process of protecting PII. Below is an example of a content warning system built into Microsoft Outlook.
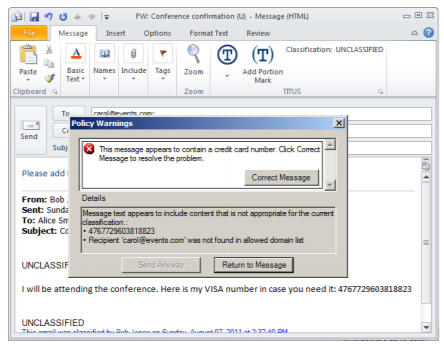
Step 3: Select the Appropriate Controls to Protect your PII
There are many NIST SP 800-53 recommended controls that can be used to protect the confidentiality of PII including access enforcement, separation of duties, remote access controls, transmission confidentiality via encryption, protection of information at rest, and more.
About TITUS
Whether it is during the creation of emails, documents, or other file types, your users become part of the solution, instead of part of the problem. TITUS allows users to identify or classify this unstructured information, and educates them on proper data handling. Because the information is identified, organizations can better manage and secure their information and meet their data governance and compliance requirements. TITUS is uniquely positioned to meet the classification requirements of government and military customers. As the leading provider of user-based email and document classification solutions, TITUS offers a complete classification management solution for the Microsoft Office platform.
Related Blog Posts

















































